
简介
什么是 Celery
Celery 是一个简单,灵活、可靠的分布式任务执行框架,可以支持大量任务的并发执行。Celery 采用典型生产者和消费者模型。生产者提交任务到任务队列,众多消费者从任务队列中取任务执行
它的核心功能是:
- 异步执行:把一些“慢任务”扔到后台去跑,不影响主程序的响应速度
- 定时任务:像闹钟一样,到点了自动触发执行任务
Celery 的基本组成
- Broker(消息中间件):任务的“中转站”,比如 RabbitMQ、Redis
- Worker(工作进程):真正执行任务的工人
- Task(任务):你定义好的需要异步执行的函数
- Result Backend(结果存储)(可选):存放任务的执行结果,比如也用 Redis、数据库等
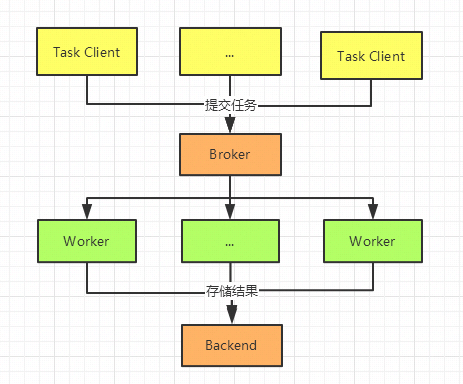
Celery 的应用场景
- 发邮件(用户注册后异步发送邮件)
- 视频转码(上传完视频后后台慢慢处理)
- 周期性操作(比如每天凌晨清理数据库)
- 接口超时保护(主线程快速返回,慢处理放到后台)
快速开始
- 安装
uv init # 使用 uv 创建一个虚拟环境
uv add celery # 安装 celery 库
如果你不知道 uv 是什么?你可以使用 pip 或者看一下这篇博客
- 简单示例
from celery import Celery
app = Celery('tasks', broker='redis://localhost:6379/0')
@app.task
def add(x, y):
return x + y
- 启动 Celery
uv run celery -A tasks worker --loglevel=INFO
注意:你不能在 windows 电脑上启动 Celery,不支持
如果你看到类似一下的内容那么启动 成功
-------------- celery@MBP.local v5.5.1 (immunity)
--- ***** -----
-- ******* ---- macOS-13.5-arm64-arm-64bit-Mach-O 2025-04-20 10:46:22
- *** --- * ---
- ** ---------- [config]
- ** ---------- .> app: tasks:0x106df8590
- ** ---------- .> transport: redis://localhost:6379/0
- ** ---------- .> results: disabled://
- *** --- * --- .> concurrency: 8 (prefork)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> celery exchange=celery(direct) key=celery
[tasks]
. tasks.add
[2025-04-20 10:46:23,109: INFO/MainProcess] Connected to redis://localhost:6379/0
[2025-04-20 10:46:23,111: INFO/MainProcess] mingle: searching for neighbors
[2025-04-20 10:46:24,120: INFO/MainProcess] mingle: all alone
[2025-04-20 10:46:24,135: INFO/MainProcess] celery@MBP.local ready.
最重要的一个标记是,你看add函数被 Celery 托管了。
设置热重载开发脚本
先说答案:严格来说,Celery 没有“真正意义上的热启动”。但是,可以通过一些技巧,做到“快速重载、不中断任务处理”,接近热启动的体验
uv add watchdog
uv run watchmedo auto-restart --pattern="*.py" --recursive -- celery -A tasks worker --loglevel=info
利用 watchdog 包,监听 python 文件的变化,一变化就重新启动 Celery
这只能在开发环境使用,请不要在生产环境使用
基本任务管理
绑定任务本身
from celery import Celery
app = Celery('tasks', broker='redis://localhost:6379/0')
import logging
_logger = logging.getLogger(__name__)
@app.task(bind=True)
def add(self, x, y):
_logger.info(f"Task ID: {self.request.id}")
return x + y
如果加了 bind=True,函数第一个参数就变成了 self(代表任务对象),你可以在任务里调用 self.retry()、self.request 这些高级功能。
设置任务的执行超时时间
from celery import Celery
app = Celery('tasks', broker='redis://localhost:6379/0')
# app.config_from_object('celeryconfig')
import logging
import time
_logger = logging.getLogger(__name__)
@app.task(bind=True, time_limit=3)
def add(self, x, y):
_logger.info(f"Task ID: {self.request.id}")
time.sleep(5) # Simulate a long-running task
return x + y
允许任务重试
@app.task(
autoretry_for=(ConnectionError,),
retry_kwargs={'max_retries': 3, 'countdown': 5},
retry_backoff=True
)
def fetch_data_from_api(url):
# 向某接口请求数据
...
autoretry_for: 指定遇到哪些异常时自动重试
retry_kwargs: 设置最大重试次数、重试等待时间
retry_backoff: 每次重试,等待时间指数级增长(比如 5 秒, 10 秒, 20 秒…)
自定义任务名称
默认任务名是 模块名.函数名,比如 tasks.add,你可以自己给任务起一个短一点的名字
@app.task(name="我的自定义任务")
def add(x, y):
return x + y
实现任务优先级
注意,我们这里使用的 broker 是 Redis,不支持原生的优先级任务队列,不过我们可以使用参数设置
- 要靠建多个队列(比如:high、medium、low)
- 不同优先级的任务投到不同队列
- Worker 根据策略消费
@app.task(queue='high_priority')
def send_alert(msg):
...
然后 Worker 专门监听 high_priority:
celery -A proj worker -Q high_priority,default
这并不是真正的优先级队列,但是面对九成的情况下应该够用了。
高级任务管理
之前的示例中,我们只介绍了 delay 方法调用 celery 任务,现在我们要介绍一个更高级的方法apply_async方法。简单来说,
delay 是 apply_async 的简化版
任务延迟执行
from tasks import add
add.apply_async((4, 4), countdown=30) # 30秒后执行
指定时间执行
from datetime import datetime, timedelta
future_time = datetime.utcnow() + timedelta(minutes=10)
add.apply_async((4, 4), eta=future_time) # 10分钟后执行
任务超时自动取消
add.apply_async((4, 4), countdown=60, expires=90)
# 任务60秒后执行,如果90秒后还没执行,就不执行了
任务优先级
如果 Broker 支持,比如 RabbitMQ,任务可以有优先级。Redis 默认不支持(需要多队列模拟)
add.apply_async((4, 4), priority=9) # 数字越大,优先级越高
重试任务
add.apply_async(
(2, 2),
retry=True,
retry_policy={
'max_retries': 5, # 最多重试5次
'interval_start': 0, # 初始重试等待0秒
'interval_step': 0.2, # 每次增加0.2秒
'interval_max': 5, # 最大重试间隔5秒
}
)
任务链与工作流
简介
多个任务串联/组合起来,按照一定的执行顺序、规则运行。就像做菜,先切菜 → 再炒菜 → 最后装盘,一步步来!在 Celery 里,这种组合多个任务执行的方式,就叫做:
- 链(chain):一个任务接一个任务执行(顺序)
- 组(group):一批任务同时并行执行(并发)
- 链组混合(chord):先一批并行跑完,再继续下一步
- 嵌套复杂工作流:chain、group、chord 混合使用
任务链 chain(顺序执行)
多个任务,一个接一个执行,每个任务的输出作为下一个任务的输入
from celery import chain
@app.task
def add(x, y):
return x + y
@app.task
def multiply(x, y):
return x * y
@app.task
def subtract(x, y):
return x - y
# 执行:先加,再乘,再减
workflow = chain(
add.s(2, 3), # 2 + 3 = 5
multiply.s(10), # 5 * 10 = 50
subtract.s(7) # 50 - 7 = 43
)
workflow.apply_async()
并发任务
group 允许你将多个任务包装在一起并并行执行。每个任务会异步地执行,并且 group 会在所有任务完成后返回一个结果列表
@app.task
def add(x, y):
return x + y
@app.task
def multiply(x, y):
return x * y
@app.task
def subtract(x, y):
return x - y
@app.task
def execute_group():
# 使用 group 执行多个任务
result = group(add.s(2, 3), multiply.s(4, 5), subtract.s(10, 5))()
return result # 获取所有任务的结果
并发完成后继续执行新任务
先并行执行一批任务,全部执行完再统一执行下一步任务。这个方法需要设置结果后端
from celery import Celery, chain, group
app = Celery('tasks', broker='redis://localhost:6379/0', backend='redis://localhost:6379/0')
import logging
import time
from celery import chord
@app.task
def fetch_data(x):
return x * 2
@app.task
def aggregate(results):
print(f"所有结果:{results}")
# 先并行 fetch_data,然后聚合
workflow = chord(
[fetch_data.s(i) for i in range(5)], # 并行执行 5个任务
aggregate.s() # 全部完成后聚合处理
)
workflow.apply_async()
定时任务
Celery 是一个强大的分布式任务队列,它不仅支持异步任务执行,还能够管理定时任务。Celery 定时任务通常使用 Celery Beat 来实现,Celery Beat 是 Celery 的一个附加组件,用于定时调度任务
快速开始
(依赖多到吓人 👻 感觉还是不用为好)
uv add beat # 安装 beat
- 简单示例
@app.task
def add(x, y):
return x + y
# 配置定时任务
app.conf.beat_schedule = {
'add-every-10-seconds': {
'task': 'tasks.add',
'schedule': 1, # 每1秒钟执行一次
'args': (16, 16), # 任务参数
},
}
app.conf.timezone = 'Asia/Shanghai'
除此这外,你还需要额外启动 beat 进程
uv run celery -A tasks beat --loglevel=info
使用 crontab 配置
from celery.schedules import crontab
app.conf.beat_schedule = {
'add-every-day-at-noon': {
'task': 'tasks.add',
'schedule': crontab(minute=0, hour=12), # 每天中午12点执行
'args': (16, 16),
},
}
我为啥不直接使用 crontab 🤪
定时任务重试机制
@app.task(bind=True, max_retries=3, default_retry_delay=5)
def add(self, x, y):
try:
print(f"Adding {x} + {y}")
return x + y
except Exception as exc:
raise self.retry(exc=exc)
Worker 高级配置
并发数设置
决定 Worker 可以同时处理多少个任务。默认值是机器 CPU 核心数。
可以手动调整:
celery -A proj worker --concurrency=16
经验建议:
- CPU 密集型任务(如图像处理):
CPU核心数 × 2 - IO 密集型任务(如 API 请求):可以调到几百、上千,结合 gevent/eventlet
任务预取
Worker 一次最多提前拉多少个任务到本地
worker_prefetch_multiplier = 1
任务执行时间长/不稳定时,prefetch_multiplier=1 是最佳实践,避免个别 worker 抢太多任务导致阻塞
子进程自动回收
每个子进程执行完一定数量任务后重启,防止内存泄漏
worker_max_tasks_per_child = 100
- 生产环境一定要设置!
- 如果你的任务本身会引起内存飙升(比如处理大图片、PDF 生成),可以把值设小一点,比如 50
任务运行时间限制
防止任务卡死或死循环
task_time_limit = 600 # 硬超时,600秒后直接杀死
task_soft_time_limit = 550 # 软超时,550秒抛异常,你可以优雅退出
区别:
- 软超时:任务可以捕获异常,优雅退出
- 硬超时:超时直接杀掉,不给你收拾残局的机会
经验:
- 一般都设置,保证 Worker 长期稳定运行
- 软超时稍短于硬超时,比如差 10% 左右
链接
- 任务队列神器:Celery 入门到进阶指南
- ChatGPT
- DeepSeek