
简介
最近在学习 Python asyncio 异步编程,但是发现其中需要的前置内容和基本概念非常多,比如 I/O 与 CPU 密集型任务的区别、并发与并行的概念、进程和线程、多任务处理、全局解释器锁(GIL)、asyncio库的使用等等。特此记录下自己的学习过程,帮助自己理解和记忆,也希望对想学习这方面知识的同学有点帮助。
如有错误,欢迎大家指正~
一、I/O 与 CPU 密集型任务
1.1 I/O 密集型
I/O密集型任务 指的是 程序的大部分时间花在等待外部资源(如磁盘、网络、数据库、文件系统等)的I/O操作 上,而不是执行CPU计算。
📌 例子
网络请求(如 HTTP API 调用、爬虫)、网络请求(如 HTTP API 调用、爬虫)、数据库查询(如 MySQL、PostgreSQL 查询)、文件读写(如读取大文件、日志处理)、磁盘I/O操作(如存储图片、视频流处理)等等。
1.2 CPU 密集型任务
CPU 密集型任务 指的是程序的大部分时间用于执行复杂的计算任务,而不是等待 I/O操作。
📌 例子
数学计算(如矩阵运算、傅里叶变换)、图片处理(如 OpenCV 图像滤波)、图片处理(如 OpenCV 图像滤波)、密码哈希计算(如加密/解密)等等
二、并发与并行
2.1 并发
当我们说两个任务并发时,是指这个任务同时发生。例如,当厨师做菜的时候,先煮饭,然后煮饭的间隙时间,可以炒菜。这两件事同时发生,但是只有一个人。
2.2 并行
虽然我们前面说并发意味着多个任务同时进行,但并不意为着它们并行运行,让我们回到做菜的例子,炒菜的时候,我们再加一个厨子,一个炒鸡蛋一个炒青菜,两个同时发生,且同时进行。
2.3 总结
在单核CPU中,并发意味着任务切换,让一个任务运行一会儿,再让另一个任务运行一会儿。单核CPU的机器中,并行并不存在。
而在多核CPU的机器中,并行意为着两个任务都是运行,一个任务在运行,另一个也在运行,不用切换。
即并行一定是并发,但并发不一定是并行。
三、进程和线程
3.1. 进程
概念:进程是程序在操作系统中运行的一个程序。每个进程有独立的内存空间、资源(如文件句柄、设备等)和执行环境。
特点:
- 每个进程是独立的,拥有自己的内存空间和资源。
- 进程之间不共享数据,通信需要使用进程间通信(IPC),如管道、消息队列等。
- 启动和销毁进程的开销较大。
3.2. 线程
概念:线程是进程内部的执行单位。每个进程至少有一个线程(主线程)。多个线程可以共享同一进程的内存和资源。
特点:
- 线程在同一个进程内共享内存空间(例如,堆内存)。
- 线程之间可以共享数据。
- 线程的创建、销毁和切换开销较小。
3.3. 进程与线程的区别
| 特性 | 进程(Process) | 线程(Thread) |
|---|---|---|
| 独立性 | 每个进程有独立的内存空间,互不干扰。 | 线程共享进程的内存空间和资源。 |
| 资源 | 拥有独立的资源(内存、文件等)。 | 共享进程的资源。 |
| 通信方式 | 进程间通信(IPC)比较复杂且开销大。 | 线程间通信高效,通常通过共享内存。 |
| 崩溃影响 | 一个进程崩溃不会影响其他进程。 | 一个线程崩溃可能导致整个进程崩溃。 |
| 开销 | 进程的创建和切换开销较大。 | 线程的创建和切换开销较小。 |
3.4. 总结
- 进程:适合需要隔离和独立执行的任务。例如,运行不同的程序。
- 线程:适合需要并发执行的任务。例如,程序内部的多个任务同时进行(如网页下载、文件读取等)。
四、多任务处理
4.1 抢占式多任务
在这个模型中,由操作系统确定多个任务的切换,主要通过使用多个线程或多个进程来实现。
4.2 协同多任务
在这个模型中,是显式的编写应用程序,调度任务的运行。
4.3 协同式多任务处理的优势
asyncio使用协同多任务来实现并发性。
当应用程序执行I/O密集型任务等待的时候,可以显示的切换到另一个任务,这是一种并发模式,不是并行模式。
协同式多任务不会像线程或进程那样需要操作系统的上下文切换,因此:
- 不需要
CPU切换成本(进程/线程切换需要保存/恢复寄存器、堆栈等)。 - 消耗更少的内存,适用于高并发(如爬虫、异步 IO 服务器)。
- 避免线程锁问题,无需担心竞争条件、死锁等问题。
五、全局解释器锁
5.1 简介
全局解释器锁是 Global Interpreter Lock即 GIL。
GIL 组织一个Python进程在同一时刻执行多个Python字节码指令。这意味着,即使在多核机器上有多个线程,Python进程一次也只能有一个线程运行Python代码。
Python 多进程可以同时运行多个字节码指令,每个 Python 进程都有自己的 GIL
GIL为什么会存在?主要是因为Cpython管理内存的方式,感兴趣的可以自行谷歌 🙂
5.2 GIL 的释放条件
当 I/O 操作发生时,GIL 会释放。但CPU密集型任务运行时不会。
至于为什么,我们后面会解释。
📌 举个例子
import time
import requests
def get_url():
response = requests.get('https://www.example.com')
print(response.status_code)
start_time = time.time()
get_url()
get_url()
end_time = time.time()
print(f'运行两个任务用时 {end_time - start_time} 秒
# 输出
# 200
# 200
# 运行两个任务用时 0.4522264003753662 秒
看,这是同步执行花费的时间,让我们用多线程程序再尝试一下
import time
import threading
import requests
def get_url():
response = requests.get('https://www.example.com')
print(response.status_code)
start_time = time.time()
t1 = threading.Thread(target=get_url)
t2 = threading.Thread(target=get_url)
t1.start()
t2.start()
t1.join()
t2.join()
end_time = time.time()
print(f'运行两个任务用时 {end_time - start_time} 秒')
# 200
# 200
# 运行两个任务用时 0.23043560981750488 秒
这比非多线程版本,大概快了一倍。
那么,回到我们前面的问题,为什么在运行 I/O 任务的时候,会释放 GIL 呢?
这主要是因为,运行 I/O 任务时,CPU 不直接与 Python 操作对象,这种时候,GIL只有在接收到的数据变成 Python 对象的时候才会重新获取。
也就是说,在 Python 中,因为 GIL 的存在,我们最多并行化 IO 操作,从而提升运行效率,而对于 CPU 操作,因为 GIL 的存在 Python 提升不了效率 🙃🙃
5.3 asyncio 与 GIL
因为asyncio是单线程并发模型,所以它是利用释放I/O提供并发性,提升性能。
所以,asyncio 依然限制于 GIL,对于 CPU 密集型任务,它还是无能为力,还是需要使用 Python 多进程来处理
5.4 异步编程为何效率高
前面解释过原因了。一图胜千言:
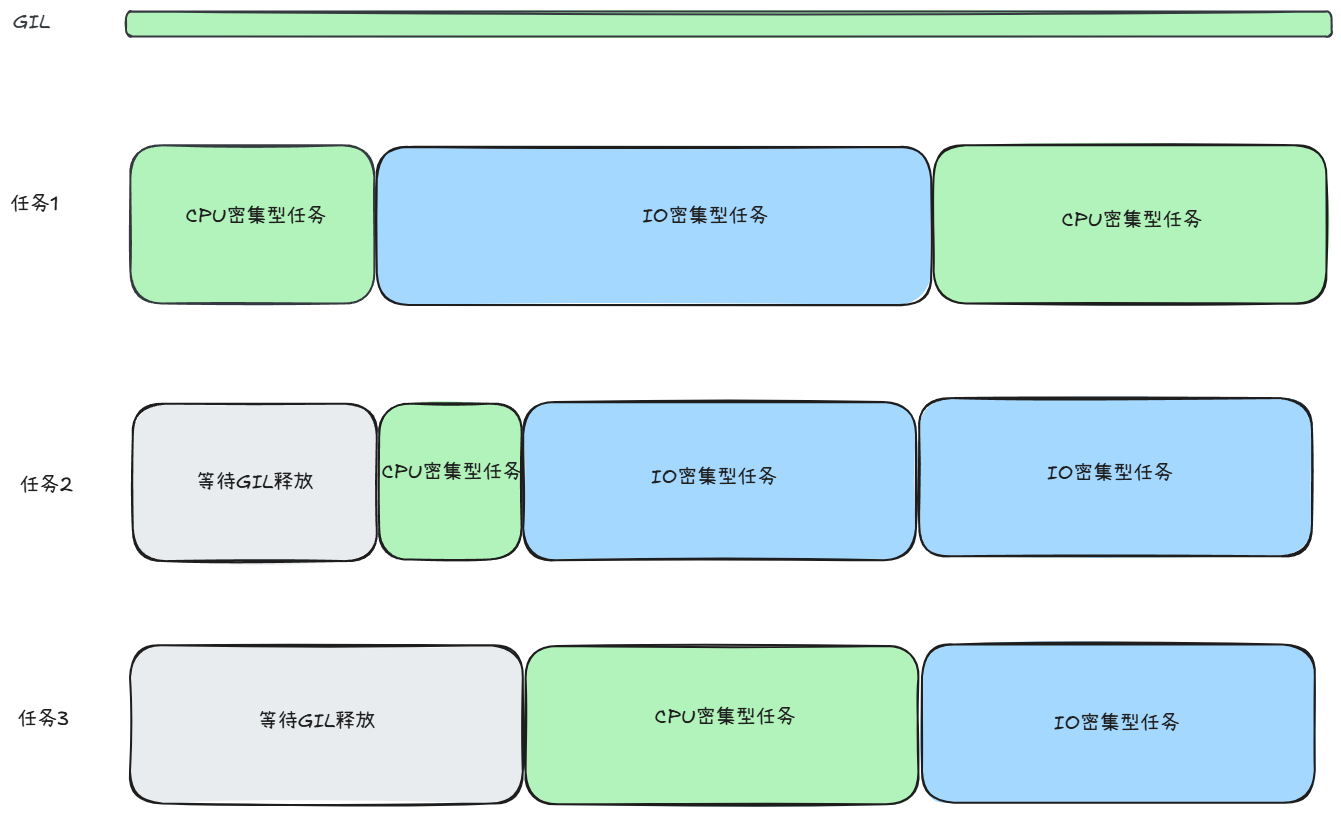
仔细看,蓝色重叠部分就是异步处理节约的I/O处理时间。也是效率高的原因。
六、Python asyncio 异步编程
6.1 asyncio 是什么
asyncio是Python标准库中的一个异步I/O框架。但从python3.4开始引入,到 python3.7 的成熟,asyncio 其实已经推出许多年了。它是单线程并发模型,主要用于I/O密集型任务
6.2 简单的使用
import asyncio
async def main():
print('hello')
await asyncio.sleep(1)
print()
asyncio.run(main())
6.3 asyncio.run()做了什么?
- 创建事件循环
- 运行传入的协程
- 关闭事件循环
6.4 asyncio 的优点
之前我们说了,asyncio的并发模型是单线程并发模型,那你知道跟多线程相比,asyncio的优点是什么嘛 🙃
asyncio使用协程来实现并发,协程是轻量级的任务单元,共享同一个线程的栈空间,创建和切换的开销远小于线程。这使得asyncio能够支持更多的并发任务,特别适合高并发的应用场景。asyncio是单线程的,协程在事件循环中按顺序执行,避免了多线程编程中常见的竞态条件问题。因此,开发者无需担心线程安全问题,代码更加简单和安全。- 相比于多线程编程,
asyncio提供了更简单的并发模型。多线程编程需要考虑线程的创建、同步和通信等问题,代码复杂且难以调试。而asyncio使用async/await语法,代码结构清晰,逻辑简单,开发者可以像写同步代码一样写异步代码,降低了并发编程的复杂性。 asyncio具有更好的扩展性。由于线程的开销较大,系统能够支持的线程数量有限,多线程模型在处理大量并发连接时可能会遇到瓶颈。而asyncio可以轻松支持成千上万的并发协程,非常适合高并发的应用场景,如 Web 服务器、网络爬虫等。
七、如何运行一个协程函数
注意:简单地调用一个协程并不会使其被调度执行
>>> main()
<coroutine object main at 0x1053bb7c8>
7.1 asyncio.run
前面介绍过了
7.2 await
await关键字后面运行协程函数。
注意:await关键字只能在协程函数内部使用,它是不能在普通函数内部使用的。
import asyncio
import time
async def say_after(delay, what):
await asyncio.sleep(delay)
print(what)
async def main():
print(f"started at {time.strftime('%X')}")
await say_after(1, 'hello')
await say_after(2, 'world')
print(f"finished at {time.strftime('%X')}")
asyncio.run(main())
实际运行上面的代码,你会发现总共用时 3 秒左右,而不是 2 秒,我们的目的是想让上述代码并发的运行,总用时应该在 2 秒左右对吧,那么为什么会用时 3 秒呢?
这是因为 await关键字,会交出当前协程函数的控制权,暂停当前协程,也就是说 main函数被阻塞了,得等第一个 say_after运行结束之后,才能运行第二个 say_after函数。
换句话说,await关键字的作用会阻塞当前协程,将异步变同步。
那想并发直接两个协程函数怎么办呢?看下面。
7.3 asyncio.create_task
import asyncio
import time
async def say_after(delay, what):
await asyncio.sleep(delay)
print(what)
async def main():
task1 = asyncio.create_task(
say_after(1, 'hello'))
task2 = asyncio.create_task(
say_after(2, 'world'))
print(f"started at {time.strftime('%X')}")
# 等待直到两个任务都完成
# (会花费约 2 秒钟。)
await task1
await task2
print(f"finished at {time.strftime('%X')}")
asyncio.run(main())
运行这段代码,你会发现用时 2 秒左右。
这是因为,使用 create_task函数,会将当前协程函数包装到 Task类中,然后交给事件循环,事件循环运行时,会并发调度两个协程函数,达到减少花费用时的目的。
7.4 asyncio.TaskGroup
async def main():
async with asyncio.TaskGroup() as tg:
task1 = tg.create_task(
say_after(1, 'hello'))
task2 = tg.create_task(
say_after(2, 'world'))
print(f"started at {time.strftime('%X')}")
# 当存在上下文管理器时 await 是隐式执行的。
print(f"finished at {time.strftime('%X')}")
Python3.11 新增功能
八、可等待对象
如果一个对象可以在await语句中使用,那么它就是 可等待对象。
可等待对象有三种主要类型: 协程对象,Task 和 Future
8.1 协程
Python 协程属于可等待对象,因此可以在其他协程中被等待
import asyncio
async def nested():
return 42
async def main():
# 如果我们只调用 "nested()" 则无事发生。
# 一个协程对象会被创建但是不会被等待,
# 因此它 *根本不会运行*。
nested() # 将引发 "RuntimeWarning"。
# 现在让我们改为等待它:
print(await nested()) # 将打印 "42"。
asyncio.run(main())
8.2 Task
Task 被用来“并行的”调度协程
当一个协程通过asyncio.create_task等函数被封装为一个 Task,该协程会被自动调度执行:
import asyncio
async def nested():
return 42
async def main():
# 将 nested() 加入计划任务
# 立即与 "main()" 并发运行。
task = asyncio.create_task(nested())
# 现在可以使用 "task" 来取消 "nested()" 或 简单地等待它直到它被完成:
await task
asyncio.run(main())
8.3 Future
Future是一种特殊的低层级可等待对象,表示一个异步操作的最终结果。
当一个Future对象被等待,这意味着协程将保持等待直到该Future对象在其他地方操作完毕。
在asyncio 中需要 Future 对象以便允许通过 async/await 使用基于回调的代码。
Future对象有时会用来包装普通函数,用作可等待对象。
通常情况下没有必要 在应用层级的代码中创建Future对象。
- 一个
Future的示例
async def main():
# 获取当前事件循环
loop = asyncio.get_running_loop()
# # 创建一个任务(Future对象),这个任务什么都不干。
fut = loop.create_future()
# 等待任务最终结果(Future对象),没有结果则会一直等下去。
await fut
asyncio.run(main())
运行上面的代码,你会发现程序卡死了,上面说了,Future对象一定要被设置一个值,否则会一直等待,现在,让我们改写一下
import asyncio
async def set_after(fut):
await asyncio.sleep(2)
fut.set_result("666")
async def main():
# 获取当前事件循环
loop = asyncio.get_running_loop()
# 创建一个任务(Future对象),没绑定任何行为,则这个任务永远不知道什么时候结束。
fut = loop.create_future()
# 创建一个任务(Task对象),绑定了set_after函数,函数内部在2s之后,会给fut赋值。
# 即手动设置future任务的最终结果,那么fut就可以结束了。
await loop.create_task(set_after(fut))
# 等待 Future对象获取 最终结果,否则一直等下去
data = await fut
print(data)
asyncio.run(main())
上面的程序就可以正常运行了,并且返回结果 “666”
- 使用
Future包装普通函数
上面我们说过,Future可以包装普通函数,成为可等待对象,让我们举个例子:
import asyncio
def sync_task(fut):
"""普通同步函数,模拟计算任务"""
result = sum(range(10**6)) # 计算大数求和
fut.set_result(result) # 手动设置 Future 结果
async def main():
loop = asyncio.get_running_loop()
fut = loop.create_future()
# 在事件循环的线程池中运行同步函数
loop.run_in_executor(None, sync_task, fut)
print("等待计算结果...")
result = await fut # 等待 Future 结果
print("计算完成:", result)
asyncio.run(main())
注意哦,这是使用线程池的方式来运行普通同步函数,不是时间循环
如果你使用的是python3.9以上的版本,还有个简单的写法
import asyncio
def sync_task():
"""普通同步函数,模拟计算任务"""
result = sum(range(10**6)) # 计算大数求和
return result # 直接返回结果
async def main():
print("等待计算结果...")
# 使用 asyncio.to_thread() 让同步函数变成可等待对象
result = await asyncio.to_thread(sync_task)
print("计算完成:", result)
asyncio.run(main())
九、并发运行 Task
asyncio.gather(*aws, return_exceptions=False)
我们看 2.3 的例子,其实有简单点的写法。
gather方法。
如果 return_exceptions 为 False (默认),所引发的首个异常会立即传播给等待 gather() 的任务。aws 序列中的其他可等待对象 不会被取消 并将继续运行。
如果 return_exceptions 为 True,异常会和成功的结果一样处理,并聚合至结果列表。
import asyncio
import time
async def say_after(delay, what):
await asyncio.sleep(delay)
print(what)
async def main():
print(f"started at {time.strftime('%X')}")
# 等待直到两个任务都完成
# (会花费约 2 秒钟。)
L = await asyncio.gather(
say_after(1, 'hello'),
say_after(2, 'world')
)
print(L)
print(f"finished at {time.strftime('%X')}")
asyncio.run(main())
但是这种方法,还是和create_task有点儿区别
| 功能 | asyncio.create_task() |
asyncio.gather() |
|---|---|---|
| 任务创建方式 | 创建独立运行的任务 | 启动多个任务并收集结果 |
| 返回值 | Task 对象 |
任务的结果列表 |
| 是否立即执行 | ✅ 立即执行,不等待 await |
❌ 只有 await gather() 时才执行 |
| 是否能取消 | ✅ 可以单独 task.cancel() |
❌ 不能取消单个任务,只能 cancel() 整个 gather() |
| 适用场景 | 让任务并行运行,不关心结果 | 多个任务并行运行,并需要所有结果 |
十、事件循环
事件循环是asyncio异步编程的核心,它的内部基本上是:
实现了一个任务调度器,维护一个任务队列,不断遍历这个任务队列,将需要等待的函数依序放入一个 sleep 队列,对无需等待的函数立刻运行。
更多的关闭事件循环的内容,推荐你看下面的视频了解:
现在,让我为你介绍几个常用的时间循环的方法
10.1 获取事件循环
get_running_loop
以下低层级函数可被用于获取、设置或创建事件循环
asyncio.get_running_loop()
返回当前 OS 线程中正在运行的事件循环。
如果没有正在运行的事件循环则会引发 RuntimeError
此函数只能由协程或回调来调用。
get_event_loop
asyncio.get_event_loop()
获取当前事件循环。
当在协程或回调中被调用时(例如通过 call_soon 或类似 API 加入计划任务),此函数将始终返回正在运行的事件循环。
如果没有设置正在运行的事件循环,此函数将返回 get_event_loop_policy().get_event_loop() 调用的结果。
由于此函数具有相当复杂的行为(特别是在使用了自定义事件循环策略的时候),更推荐在协程和回调中使用 get_running_loop()函数而非 get_event_loop()
请考虑使用高层级的asyncio.run()函数,而不是使用这些低层级的函数来手动创建和关闭事件循环。
自 3.12 版本弃用: 如果没有当前事件循环则会发出弃用警告。 在未来的 Python 发布版中这将被改为错误。
10.2 创建一个事件循环
import asyncio
async def say_later(delay, msg):
await asyncio.sleep(delay)
print(msg)
return msg
async def main():
res = await asyncio.gather(say_later(1, 'hello'), say_later(2, 'world'))
print(res)
# ✅ 适用于 Python 3.6 及以下
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
loop.run_until_complete(main())
loop.close()
注意:这个示例只适用 python3.6以下的版本,如果是 python3.7以后的版本,就可以使用 asyncio.run方法直接调用,无需手动创建事件循环。
十一、在线程或者进程池中执行代码
concurrent.futures这个对象是基于线程池和进程池实现异步操作时使用的对象。一般用于将不支持异步函数操作的第三方模块改造为支持异步操作。
一般来说,我们使用线程池执行I/O密集型任务,使用进程池执行CPU密集型任务。
import asyncio
import concurrent.futures
def blocking_io():
# 文件操作(如日志记录)会阻塞事件循环:
# 应在线程池中运行它们。
with open('/dev/urandom', 'rb') as f:
return f.read(100)
def cpu_bound():
# CPU 密集型操作会阻塞事件循环:
# 通常建议在进程中运行它们。
return sum(i * i for i in range(10 ** 7))
async def main():
loop = asyncio.get_running_loop()
## Options:
# 1. 运行默认循环的执行器:
result = await loop.run_in_executor(
None, blocking_io)
print('default thread pool', result)
# 2. 在自定义的线程池中运行:
with concurrent.futures.ThreadPoolExecutor() as pool:
result = await loop.run_in_executor(
pool, blocking_io)
print('custom thread pool', result)
# 3. 在自定义的进程池中运行:
with concurrent.futures.ProcessPoolExecutor() as pool:
result = await loop.run_in_executor(
pool, cpu_bound)
print('custom process pool', result)
if __name__ == '__main__':
asyncio.run(main())